Bandits!
Today we’re talking about bandits. Bandit problems, not dissimilar from Markov chains, are one of those simple models that apply to a wide variety of problems. Indeed, many results of “sequential decision making” stem from the study of bandit problems. Plus the name is cool, so that should provide some motivation for wanting to study them. The name bandit originates from the term one-armed bandit, which was used to describe slot machines.
In their survey on bandits, Bubeck and Cesa-Bianchi define a multi-armed bandit problem as “a sequential allocation problem defined by a set of actions.” The allocation problem is similar to a (repeated) game: at each point in time, the player chooses an action i.e., an arm, and receives a reward.
The player’s goal is to maximize her cumulative reward, which naturally leads to an exploitation vs. exploration problem. The player needs to simultaneously exploit arms known to yield high rewards and explore other arms in the hopes of finding other high-yield rewards.
In bandit problems, we assess a player’s performance by her regret, which compares her performance to (something like) the best-possible performance. After the first rounds of the game, the player’s regret is
where is the number of bandit arms, is the reward of arm at time , and is the player’s (possibly randomly) chosen arm.
Stochastic bandit problems
In this post, we’re going to focus on stochastic bandit problems as opposed to adversarially bandit problems. Here’s the set-up.
- There are arms.
- Each arm corresponds to an unknown probability distribution .
- At each time , the player selects an arm (independently of previous choices) and receives a reward .
We’ll denote the mean of distribution with and define
as optimal parameters. Instead of using the regret to assess our player’s performance, we’ll use the pseudo-regret, which is defined as
We know that because of Jensen’s inequality for convex functions. For our purposes, a more informative form of the pseudo-regret is
where is the suboptimality of arm and the random variable is the number of times arm is selected in the first rounds.
This alternative expression for the pseudo-regret sums over arms rather than rounds. To see how we switched from arms to rounds, play around with random variables .
Upper confidence bounds
One approach for simultaneously performing exploration and exploitation is to use upper confidence bound (UCB) strategies. UCB strategies produce upper bounds (based on a confidence level) on the current estimate for each arm’s mean reward. The player selects the arm that is the best using the UCB-modified estimate.
In the spirit of brevity, we’re going to gloss over a few important details (e.g., Legendre–Fenchel duals and Hoeffding’s lemma) but here’s the gist of the UCB set-up.
- Define as the sample mean of arm after being played times.
- For a convex function with convex conjugate and parameter , the cumulant generating function of is bounded by :
- By Markov’s inequality and the Cramér–Chernoff technique
- Markov’s inequality means that, with probability , we have an upper bound on the estimate of the th arm:
The UCB strategy is (very) simple; at each time , select the arm by
The tradeoff. Let’s pick apart this term and see how it encourages exploration and exploitation. We’re going to use with convex conjugate , so that .
When arm has not been played many times before time $t$, i.e., when is small numerator of dominates and the UCB-adjusted estimate of arm is likely to relatively high, which encourages arm to be chosen. In other words, it encourages exploration.
As arm is chosen more, increases and the estimate improves. If arm is the optimal arm, then the term dominates the estimates for other arms and the UCB-adjustment further encourages selection of this arm. This means that the algorithm exploits high-yielding arms.
Upper bound on pseudo-regret. If our player follows the UCB scheme specified above, then for her pseudo-regret is upperbounded as
We’re going to prove the bound in the next post.
Bandit simulations
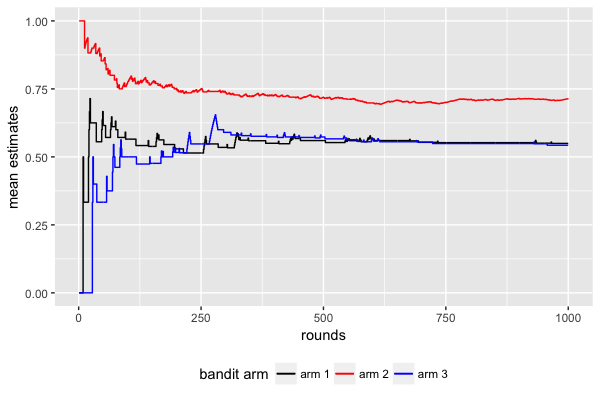
Here’s an R script which uses the upper confidence bound algorithm. For the plots below, there are arms and rounds. The reward distributions are Bernoulli’s and the mean parameters the three arms are 0.46, 0.72, and 0.55.
The first plot shows the evolution of each mean estimate as different rounds are
played.
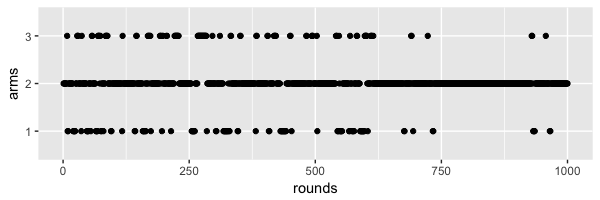
The next plot illustrates the exploration vs. exploitation trade-off. Even
though arm 2 yields the highest rewards, the algorithm occasionally plays
arms 1 and 3 in later rounds.
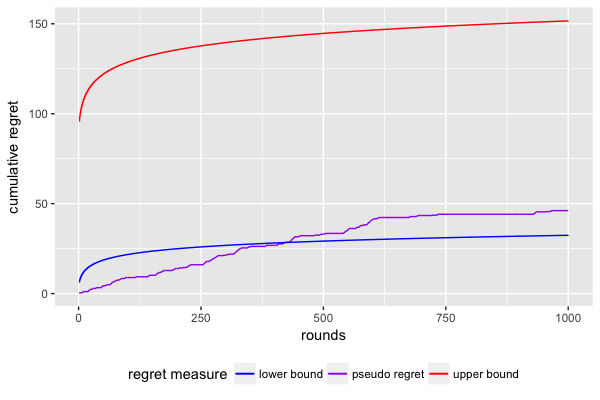
The final plot shows the player’s cumulative regret compared to the UCB-implied
upper bound on the regret; the lower bound is distribution-dependent and
asymptotic, which is why it exceeds the pseudo-regret until round 400ish.
Next up
… a proof of the upper confidence bound regret rate!
References
This post is based on material from:
- Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems by S. Bubeck and N. Cesa-Bianchi. A digital copy can be found here.
- Prediction, Learning, and Games (a.k.a. “Perdition, Burning, and Flames”) by N. Cesa-Bianchi and G. Lugosi. Find a description of the book and its table of contents here.
I would also recommend checking out Sébastien Bubeck’s blog “I’m a bandit” and, in particular, his bandit tutorials: part 1 and part 2. Also check out his new YouTube channel: https://www.youtube.com/user/sebastienbubeck/videos.